

Les raisons d’une gestion distribuée de vos fichiers, aujourd’hui
Ce texte est une traduction d’un article du blog James on Software, écrit par James Golick, un développeur web basé à Montréal, et publié le 20 janvier 2008. Il nous montre une application des réseaux centralisé, décentralisés et distribués, appliquée à la gestion de version de fichiers.
Depuis que Linus Torvald (initiateur de Linux) vous parle de git, vous vous demandez sûrement de quoi il veut parler, vous n’êtes pas les seuls.
La gestion distribuée de version de fichier est l’un des concept logiciel des moins bien compris, aujourd’hui. Il y a beaucoup de geeks qui vous diront que vous devriez l’utiliser, mais personne n’a encore réussi a expliquer pourquoi. Alors je m’y essaye.
Mais de quoi nous parle Linus?
Premièrement, voyons ce qu’est une gestion distribué de version de fichier. L’approche la plus commune pour décrire un système décentralisé est de présenter une image comme celle-ci, qui vient d’une page du manuel de Mercurial, appelée ComprendreMercurial (en anglais):
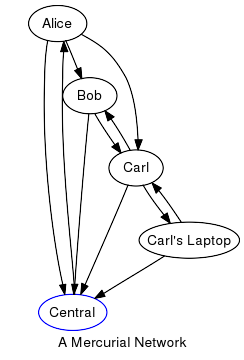
Si vous comprenez cette image (et que vous êtes nouveau dans la gestion de version de fichier), félicitations. Pour les autres, continuons avec une description plus claire.
Commençons par voir les différence entre la gestion centralisée et la gestion décentralisée de version de fichier. Avec un système centralisé comme Subversion ou CVS, il n’y a qu’*une seule copie du dépôt* de fichier (endroit où tous les fichiers sont stockés); cette copie est généralement placé sur un serveur accessible à plusieurs personnes. Quand un développeur travaille sur le code, il crée ce qu’on appelle une “copie de travail” (“checkout”) depuis le dépôt central. Cette copie contient assez d’information pour permettre au développeur d’interagir avec le serveur central, mais elle ne contient pas l’historique des révisions du projet, ni les branches ou les tags qui ont été créés (bien que ces branches et tags peuvent être explicitement demandés).
Avec un système décentralisé, l’opposé est vrai. Au lieu de demander une copie de travail, le développeur travaille sur une copie de l’intégralité du dépôt de fichier, qui inclut l’historique complet des révisions du projet ainsi que toutes les branches et tags. La copie que le développeur reçoit est identique au dépôt où ils ont demandé cette copie. Les commits, branches, et tags ont lieu localement, sur la copie que les développeur ont fait. Les changements peuvent être envoyés (“push”) et reçus (“pull”) vers et depuis un dépôt public, ou la copie d’un autre développeur, ou sur n’importe quel autre dépôt qui existe.
Donc?
D’habitude, quand vous voulez la version finale ou les sources d’un projet open-source, vous vous dirigez vers le site officiel du projet. Le dépôt du projet est bien gardé, avec des privilèges pour certains développeurs qui peuvent changer le code. Celui qui voudra effectuer un changement dans le code devra d’abord récupérer une “copie de travail”, proposer un patch, et espérer qu’il soit accepté.
Quand chaque développeur a une copie complète du dépôt sur sa machine, la hiérarchie des projets open-source n’est pas pour autant supprimée. Le développeur qui veut travailler sur le code peut faire une copie du dépôt, effectuer des changements localement autant qu’il veut, recevoir les changements des copies des autres développeurs, et publier ses changements pour que les autres développeurs puissent les utiliser ou les rapatrier sur leur propre dépôt. Dans un système décentralisé, il n’y a pas de clé sur le dépôt du code source. Si l’auteur original continue de maintenir la meilleure version du code, super; sinon, les utilisateurs de ce code peuvent commencer à récupérer leur source de la personne qui offre la meilleure version.
Vraiment?
Beaucoup (peut-être la plupart) des plugins rails sont inactifs. Il ont été créés pour combler un manque, publiés, mis à jours pendant quelques mois, puis laissé a l’abandon. Puisque la plupart des plugins rails résident dans des dépôt subversion, personne ne peut continuer le développement sans perdre l’historique des révisions du projet, et avoir s’encombrer de problème pour configurer un serveur subversion public.
Markaby n’est pas une exception à cette règle. Quand j’ai voulu l’utiliser dans un projet récent, j’ai trouvé qu’il été incompatible avec rails 2.0.2. D’après les logs subversion de markaby, les derniers changements dataient du 24 novembre 2007, quelques semaines avant la publication de cette version de rails. Heureusement, j’ai retrouvé un ticket dans le support de rails, qui donnait des instructions pour fixer le plugin avec un hack – une solution qui fonctionnait bien pour moi, mais qui n’apporterait rien aux utilisateurs qui ne trouveraient pas ce cheminement autour du plugin. Normalement, sans privilèges pour changer le code de markaby sur le dépôt officiel, je ne pourrait pas offrir ce fix publiquement.
Aucun problème avec un système distribué! En utilisant git-svn pour passer Markaby sur un dépôt git, j’ai publié mes changements, et maintenant n’importe qui peut récupérer une copie de Markaby en tapant la commande suivante:
$ git clone git@github.com:giraffesoft/markaby.git
Encore plus cool, quelqu’un avec assez de privilèges sur le dépôt officiel peut récupérer les changements, et les remettre dans subversion, avec les messages des modifications inclus! Le développement de ce plugin peut continuer n’importe où, et par n’importe qui. C’est la beauté de la décentralisation.
Alex Girard
Web developer - Geek - Hacker
alx.girard@gmail.com
