Le Packfile
Ce chapitre explique en détails, au bit près, comment le packfile et les fichier d'index de pack sont formatés.
L'Index Packfile
Premièrement, nous avons l'index packfile, qui est simplement juste une série de marque-pages vers le packfile.
Il existe 2 versions de l'index packfile - version 1, qui est celle par défaut dans les version de Git antérieures à 1.6, et la version 2, qui est celle par défaut depuis Git v1.6, et qui peut être lue par Git jusqu'à la v1.5.2, et qui a aussi était portée sur la v1.4.4.5 sur vous travaillez toujours dans la série 1.4.
La version 2 inclue un checksum CRC pour chaque objet afin que les données compressées puissent être copiées directement entre les pack durant les re-package sans se retrouver avec de données corrumpues non-détectées. Les index de version 2 peuvent aussi s'occuper de packfiles supérieurs à 4Go.
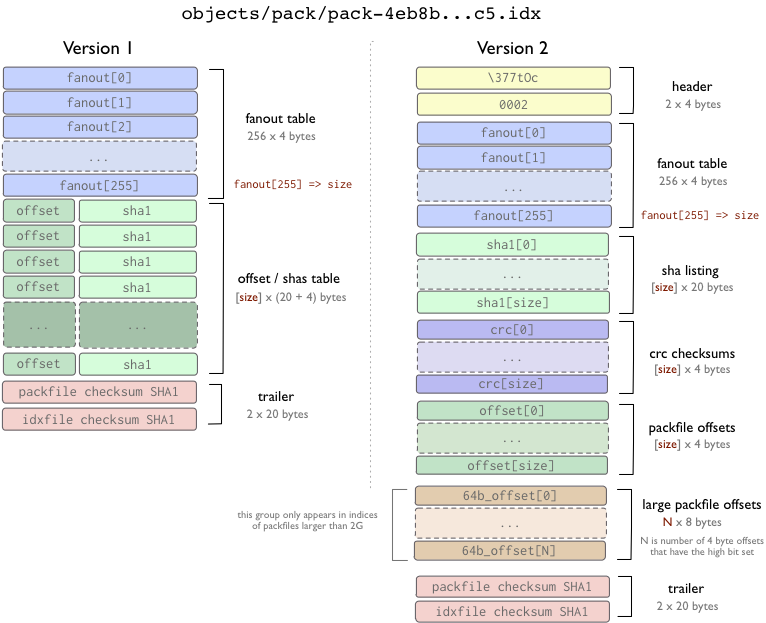
Dans les 2 formats, la table de routage (fanout) est simplement un manière plus rapide de trouver dans le fichier d'index l'offset d'un SHA particulier. Les tables offset/sha1[] sont triées par valeurs sha1[] (cela permet les recherches binaires sur cette table), et la table fanout[] pointe vers la table offset/sha1[] de façon spécifique (pour que la part de la dernière table qui convertie tous les hash commençant par un bit en particulier afin qu'ils puissent être trouvés en évitant les 8 itérations de la recherche binaire).
Dans la version 1, les offsets et SHAs sont au même endroit, alors que dans la version 2, il y a des tables séparés pour les SHAs, les checksums CRC et les offsets. Les checksums SHAs pour le fichier d'index et le packfile se trouvent à la fin de chacun de ces fichiers.
Il es important de noter que les index de packfile ne sont pas nécessaires pour extraire les objets d'un packfile, ils sont juste utilisé pour retrouver rapidement des objets individuels depuis un pack. Le format du packfile est utilisé dans les programmes upload-pack et receive-pack (protocoles de publication - push - et de récupération - fetch) pour transférer les objets, et il n'y a alors pas d'index utilisé - il peut être construit après coup en scannant le packfile.
Le Format du Packfile
Le format du packfile même est très simple. Il y a une entête, une série d'objets packagés (chacun avec sa propre entête et son propre corps), puis un checksum à la fin. Les 4 premiers bits forment a chaîne de caractère "PACK", qui est utilisée pour être sûr que vous lisez correctement le début du packfile. Ceci est suivi d'un numéro de version du packfile sur 4 bits, puis 4 autres bis représentant le nombre d'entrées dans ce fichier. En Ruby, vous pourriez lire les données de l'entête de cette manière:
def read_pack_header sig = @session.recv(4) ver = @session.recv(4).unpack("N")[0] entries = @session.recv(4).unpack("N")[0] [sig, ver, entries] end
Après ça, vous avec une suite d'objets packagés, ordonnés par leur SHA, chacun représenté par l'entête de l'objet et son contenu. Une somme SHA de 20 bits de tous les SHAs du packfile se trouve dans les 20 bits à la fin du fichier.
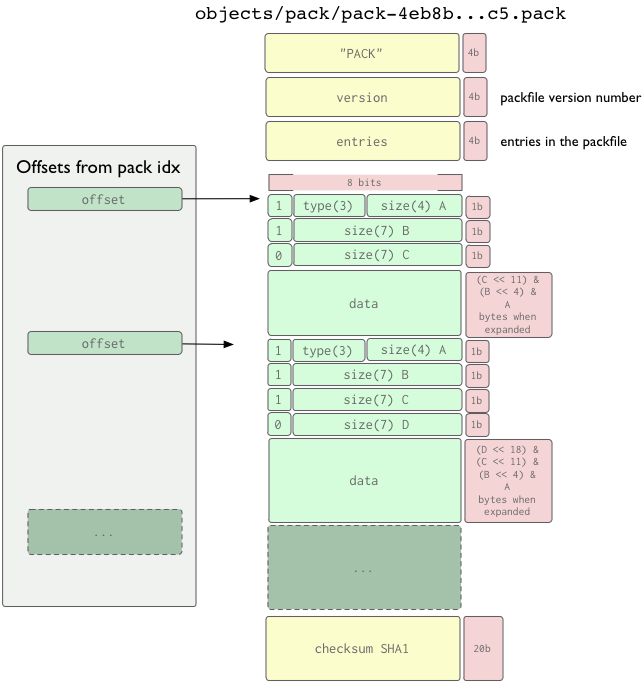
L'entête de l'objet est une série de un ou plusieurs morceaux d'octets (8 bits) qui définissent le type d'objet représenté par les données qui suivent, et la taille de l'objet quand il est décompressé. Chaque octet ne contient réellement que 7 bits de données, le premier bit ne disant que si cet octet est le dernier avant que ne commence les données. Si le premier bit est 1, vous pourrez continuer à lire le prochain octet. sinon les données commencent au prochain octet. Les 3 premiers bits du premier octet spécifient le type de données, en accord avec la table ci-dessous.
(Actuellement, sur les 8 valeurs qui peuvent être exprimées avec 3 bits (0-7), 0 (000) est 'undefined' et 5 (101) n'est pas encore utilisée.)
Nous pouvons voir ici un exemple d'entête de 2 octets, où le premier spécifie que les données suivantes sont un commit, et le le reste des bits du premier octet accompagnés de ceux du second octet spécifient que les données feront 144 octets une fois décomprimés.
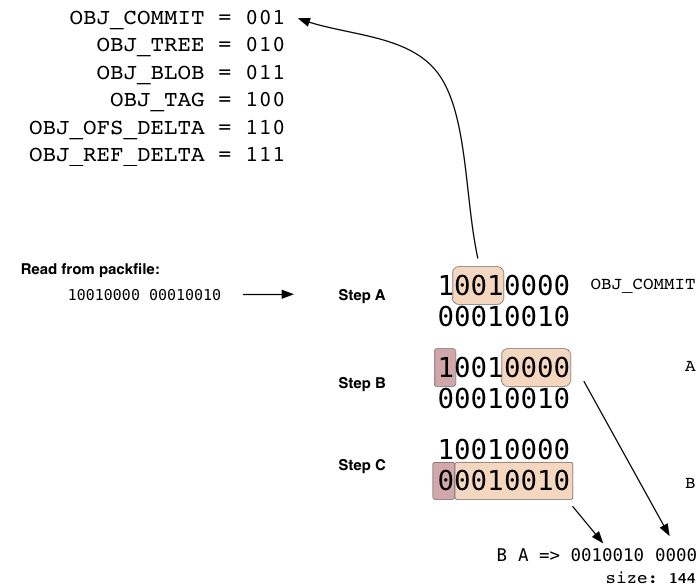
Il est important de savoir que la taille spécifiée dans les données de l'entête n'est pas la taille des données qui suivent, mais la taille des données une fois décomprimés. C'est pourquoi les offset de l'index du packfile sont si utiles, sinon vous devriez décompresser chaque objet juste pour savoir quand la prochaine entête commence.
La partie donnée n'est qu'un stream zlib pour des types d'objet non-delta;
pour la représentation de 2 objets delta, la portion de donnée contient
quelque chose qui identifie de quel objet de base dépend cet objet delta,
et le delta à appliquer sur l'objet de base pour retrouver cet objet.
ref-delta utilise un hash de 20 octets pour l'objet de base
au début des données, alors que ofs-delta stocke un offset
à l'intérieur du même packfile pour identifier l'objet de base. Dans chacun
des cas, vous devez suivre 2 contraintes importantes si vous voulez
ré-implémenter ce fonctionnement:
- la représentation du delta doit être basée sur quelqu'autre objet à l'intérieur du même packfile;
- l'objet de base doit être de même type sous-jacent (blob, tree, commit ou tag);

